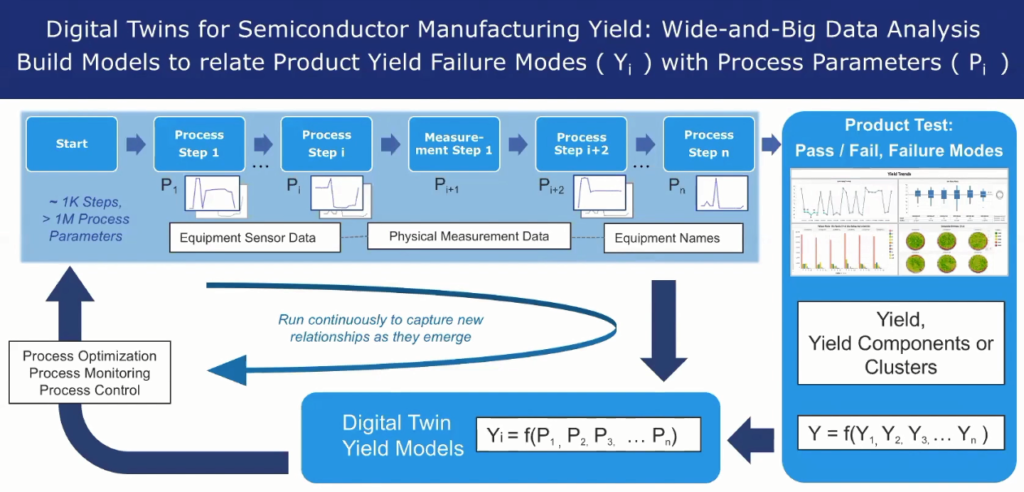
Se trata de aplicar nuevos sistemas de análisis de los millones de datos que se generan en tiempo real en la fabricación por ejemplo de semiconductores. Es el ejemplo que se pone en el webinar.
Se habla del análisis de lo que denominan en inglés “Semiconductor Manufacturing Yield” (el ratio de semiconductores defectuosos) a partir de un volúmen brutal de datos que no podrían analizarse siguiendo procedimientos tradicionales.
Se hace una demo práctica del testeo de millones de datos.
El webinar está explicado por:
– Steve Hillion, Senior Director de Data Science de Tibco
– Mike Alperin, Consultor en el sector industrial de Tibco
Estos son los capítulos del video:
Digital Twins: Key for Efficient Operations and HIgh Yield 01:00
Use Case: Digital Twin for Semiconductor Yiedl 3:19
The extreme Challenge of Big & Wide Data 06:10
Solution Arquitecture 7:46
Demo 9:45
Performance Benchmarks and Conclusions 21:37
Esta es la presentación que se hace del video:
Los gemelos digitales son representaciones virtuales de sistemas físicos. El interés actual en ellos está impulsado por la convergencia de IoT, el aprendizaje automático y la tecnología de big data. A medida que aumenta la complejidad de los procesos de fabricación se están convirtiendo en la clave para el control eficiente de operaciones de fabricación y del testeo de los productos.
Existe una demanda de soluciones analíticas de “datos amplios y grandes” que detectan asociaciones entre las métricas de calidad del producto y miles a millones de variables de proceso. Estas soluciones de vanguardia pueden admitir análisis de causa raíz y predictivos.
Además, los resultados deben estar disponibles cerca del “tiempo real” para permitir intervenciones de procesos útiles, por ejemplo, para identificar cambios sutiles en los equipos, cambios o desviaciones del proceso, o para predecir y remediar el rendimiento por debajo de un lote en la línea.
Este seminario web se enfoca en la implementación de un gemelo digital para testeo y calidad en fabricación de semiconductores que detecta asociaciones entre las métricas de calidad del producto y millones de procesos de predicción.
Lo que verás:
– Cómo se utilizan los sistemas híbridos de big data más sistemas “in memory” para abordar los diversos problemas de arquitectura analítica y de TI asociados con este desafío
– Cómo combinar capacidades analíticas distribuidas a gran escala con analíticas avanzadas integrales basadas en memoria y servidor
– Cómo entregar resultados interactivos accionables a través de visualizaciones inteligentes.